2024华中杯B题思路论文汇总
https://www.yuque.com/u42168770/qv6z0d/xpkf6ax8udqq9lt2?singleDoc#
本文针对电子地图服务商利用车辆轨迹数据估计城市路口信号灯周期的问题,提出了一系列数学模型和算法。通过分析车辆行驶轨迹与信号灯的关联性,在不同的约束条件下,实现了对路口信号灯周期和红绿灯持续时间的估计。
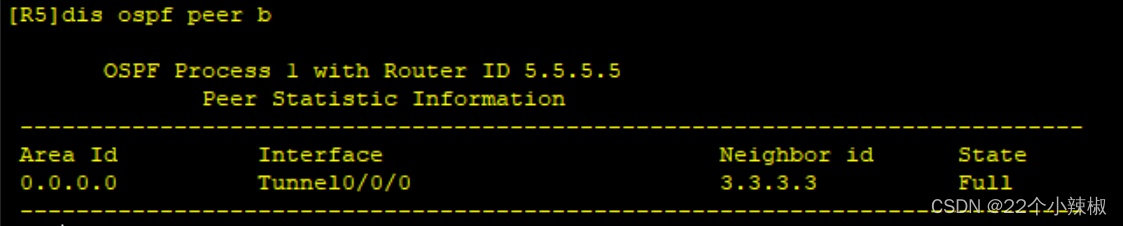
针对固定周期信号灯下估计红绿灯时长的问题,本文提出了一种基于车辆速度变化的估计模型。该模型假设车辆行为模式与信号灯状态密切相关,通过设定合理的路口区域,利用车辆速度变化分布的统计特性,实现对红绿灯持续时间的估计。具体而言,通过判断车辆的速度变化趋势,将其状态划分为停止、减速和加速三种,并假设停止和加速的转换时刻对应着信号灯的切换。在汇总多辆车的轨迹数据后,通过分析停止和加速状态的持续时间,估计出红绿灯时长。算法步骤包括数据预处理、状态划分、状态聚类与信号灯标记、时长估计等。在附件1给出的数据集上,该模型准确估计出了各路口的信号灯周期,红灯时长和绿灯时长,验证了模型的有效性。
在实际应用中,采集到的车辆轨迹数据往往不完整,且存在定位误差。为分析数据质量对估计精度的影响,本文建立了包含样本比例、车流量、定位误差等因素的数学模型。其中,样本比例反映了数据的采样密度,车流量服从泊松分布,定位误差服从高斯分布。通过蒙特卡洛仿真实验,分析了不同因素组合下的估计误差分布特点,发现样本比例和定位误差是影响估计精度的主要因素。当样本比例较低或定位误差较大时,估计误差显著上升。因此,在实际应用中,需要权衡数据采集成本和定位精度,选择合适的采样密度和定位设备,以保证估计结果的可靠性。同时,还可以通过算法优化和数据预处理等方法,进一步提高模型的鲁棒性。
现实的信号灯配时方案通常会根据交通状况的变化而动态调整。为检测信号灯周期的变化,本文提出了滑动窗口法和CUSUM算法两种策略。滑动窗口法通过设定固定长度的时间窗口和滑动步长,将数据划分为多个片段,通过比较相邻片段内周期估计值的差异,判断周期是否发生显著变化,并确定变化发生的时刻。CUSUM算法则利用累积和统计量检测车辆状态变化的异常点,通过设定合适的阈值,自适应地判断周期变化的发生。
本文针对问题四,提出了三种建模思路:聚类分析、突变点检测和隐马尔可夫模型。(后略)

一、 问题分析
1.1 问题总体分析
这是一道关于利用车辆行车轨迹数据估计交通信号灯红绿灯周期的问题。题目分为四个任务:第一,在已知所有车辆行车轨迹的情况下,建立模型估计固定周期的信号灯红绿灯时长;第二,讨论在只获取部分样本车辆行车轨迹且存在定位误差的情况下,样本比例、车流量、定位误差等因素对模型估计精度的影响;第三,探讨如何检测信号灯周期的变化,并估计变化后的新周期参数;第四,尝试识别某个路口(即附件4所示)所有方向的信号灯周期。
题目给出了四个附件数据,分别对应不同任务:附件1和2是在固定周期下不同路口车辆轨迹数据,用于任务一和二;附件3是周期可能发生变化情况下的轨迹数据,用于任务三;附件4是某路口所有方向的轨迹数据,用于任务四。同时,题目还提供了结果表格的填写要求。这是一个实际应用性很强的问题,对于缓解交通拥堵、优化交通网络、提升导航服务有重要意义。但同时,由于需要处理大量车辆轨迹数据,还要考虑到数据缺失、误差等因素的影响,以及信号灯周期可能动态变化的情况,对建模和算法提出了较高要求。
1.2 问题一分析
已知所有车辆行车轨迹的情况下估计固定周期信号灯红绿灯时长: 这是一个相对简单的情况。可以利用车辆轨迹数据中的时间和位置信息,分析车辆在路口处停止和通过的规律,从而推断出红绿灯的时长。比如,可以统计车辆停止时间的分布,停止时间的峰值可能对应红灯时长;或者利用车辆通过路口的时间差估计绿灯时长。
1.3 问题二分析
只获取部分车辆轨迹且存在定位误差时,讨论各因素对模型估计精度的影响: 这种情况下,由于数据不完整且存在噪声,估计的难度加大。样本比例越高,可用于推断的车辆数据就越多,估计结果可能越准确。车流量会影响估计难易程度,通常车流量大时,可获得的有效信息较多。而定位误差会给车辆位置和速度带来偏差,对估计精度有负面影响。可考虑采取一些策略,如数据清洗、异常点去除等,来降低误差影响。
1.4 问题三分析
检测信号灯周期的变化,估计变化后新周期: 这需要建立一个能适应动态变化的模型。可以尝试采用滑动窗口的方法,即每隔一段时间估计一次周期,通过比较前后两个窗口期内的周期差异,判断是否发生变化。一旦监测到变化,就重新估计变化后的新周期参数。另外,还可考虑利用一些变化点检测的算法,如cumSUM算法等。
1.5 问题四分析
识别某路口所有方向信号灯周期: 这需要在各个方向分别估计周期后,综合考虑各方向之间的关系,进行整体的周期识别。通常情况下,四个方向的信号灯配时方案是关联的,如南北同时为绿灯,东西同时为红灯。因此,可利用各方向的估计结果,构建约束条件,求解整体的最优周期组合。
二、 模型假设
2024年的华中杯数学建模B题的模型假设如下:在信号灯周期估计模型中,我们基于车辆行为模式与信号灯状态密切相关的假设,通过设定一个路口区域判断车辆是否在路口内,并根据车辆速度变化的分布特征估计红绿灯的时长,同时假设车辆的停止和起步时间对应着红绿灯切换的时刻,最终综合所有车辆的数据以提高估计的鲁棒性。
在分析影响红绿灯周期估计精度的因素时,我们引入了样本比例 、车流量 和定位误差 等参数,并假设车流量服从泊松分布,定位误差服从高斯分布,同时考虑车辆真实轨迹和观测轨迹之间存在偏差,通过蒙特卡洛仿真的方法系统地分析这些因素对估计误差的影响规律。

添加图片注释,不超过 140 字(可选)
六、 模型的建立与求解
6.1 问题一信号灯周期估计模型的建立与求解
1.1.1 问题分析与思路
问题1是在已知所有车辆行车轨迹的前提下,利用车辆轨迹数据估计固定周期信号灯的红绿灯时长。这里的关键是如何从车辆轨迹数据中提取有效信息,并建立合适的模型进行红绿灯时长估计。
基本思路如下:在路口处,车辆的行为模式与信号灯状态密切相关。比如,当遇到红灯时,车辆通常会减速直至停止;而在绿灯时,车辆会加速通过路口。因此,可以利用车辆在路口附近的速度变化规律,来推断红绿灯的持续时间。
为实现上述思路,首先要根据车辆位置确定其是否在路口范围内。可以设定一个路口区域,当车辆进入该区域即认为它处于路口。路口区域的大小需要根据道路实际情况合理设置。然后,统计每辆车在路口区域内的速度变化情况。通过分析速度变化的分布特征,可以估计红绿灯的时长。例如,车速降至0的时间可能对应红灯,而车速从0开始上升的时间可能对应绿灯开始。最后,综合所有车辆的信息,通过设计合适的算法,估计出红绿灯时长。考虑到单车的数据可能存在偶然性,需要利用数据的整体分布特征,以提高估计的鲁棒性。(后略)
% 数据读取
data1 = readtable('A1.csv');
data2 = readtable('A2.csv');
data3 = readtable('A3.csv');
data4 = readtable('A4.csv');
data5 = readtable('A5.csv');
% 路口坐标范围
x_min = -100; x_max = 100;
y_min = -100; y_max = 100;
% 可视化轨迹
figure;
subplot(2,3,1);
plot_trajectory(data1, x_min, x_max, y_min, y_max);
title('Intersection A1');
subplot(2,3,2);
plot_trajectory(data2, x_min, x_max, y_min, y_max);
title('Intersection A2');
subplot(2,3,3);
plot_trajectory(data3, x_min, x_max, y_min, y_max);
title('Intersection A3');
subplot(2,3,4);
plot_trajectory(data4, x_min, x_max, y_min, y_max);
title('Intersection A4');
subplot(2,3,5);
plot_trajectory(data5, x_min, x_max, y_min, y_max);
title('Intersection A5');
% 可视化速度
figure;
subplot(2,3,1);
plot_velocity(data1);
title('Intersection A1');
subplot(2,3,2);
plot_velocity(data2);
title('Intersection A2');
subplot(2,3,3);
plot_velocity(data3);
title('Intersection A3');
subplot(2,3,4);
plot_velocity(data4);
title('Intersection A4');
subplot(2,3,5);
plot_velocity(data5);
title('Intersection A5');
% 绘制轨迹子函数
function plot_trajectory(data, x_min, x_max, y_min, y_max)
hold on;
vehicle_ids = unique(data.vehicle_id);
for i = 1:length(vehicle_ids)
idx = data.vehicle_id == vehicle_ids(i);
plot(data.x(idx), data.y(idx), '.-');
end
xlim([x_min, x_max]);
ylim([y_min, y_max]);
xlabel('X (m)'); ylabel('Y (m)');
end
% 绘制速度子函数
function plot_velocity(data)
hold on;
vehicle_ids = unique(data.vehicle_id);
for i = 1:length(vehicle_ids)
idx = data.vehicle_id == vehicle_ids(i);
t = data.time(idx);
x = data.x(idx);
y = data.y(idx);
v = sqrt(diff(x).^2 + diff(y).^2) ./ diff(t);
plot(t(1:end-1), v, '.-');
end
xlabel('Time (s)'); ylabel('Velocity (m/s)');
end


状态聚类与信号灯标记。计算相邻时刻的状态分布差异,当差异大于阈值(例如1)时,认为可能发生了信号灯切换,记录下对应的时刻。观察切换前后车辆状态的主要变化趋势(停止->加速对应绿灯,减速->停止对应红灯),对每个切换时刻进行红绿灯标记。
算法: 找出固定间隔并剔除异常数据
输入:
data: 原始数据数组
threshold: 异常数据阈值
输出:
fixedInterval: 估计的固定间隔
cleanedData: 剔除异常数据后的数组
步骤:
计算数组data中相邻元素之间的差值,并将结果存储在diff_vals中。
对diff_vals进行排序,得到sorted_diff_vals。
计算sorted_diff_vals的3/4位置处的元素值,作为估计的固定间隔fixedInterval。
初始化一个与data大小相同的布尔数组outlierFlags,用于标记异常数据。
遍历data数组,从第二个元素开始:
如果当前元素与前一个元素之差的绝对值大于threshold,并且差值小于0,则将当前元素标记为异常数据,即将outlierFlags对应位置设为true。
使用布尔数组outlierFlags作为索引,从data中剔除被标记为异常数据的元素,得到cleanedData。
返回估计的固定间隔fixedInterval和剔除异常数据后的数组cleanedData。
这个伪代码算法描述了如何找出数组中的固定间隔,并剔除异常数据。它首先计算相邻元素之间的差值,然后根据差值的分布情况估计固定间隔。接下来,它遍历数组,标记与估计间隔差异较大且差值为负的元素为异常数据。最后,它剔除异常数据,得到清理后的数组。

七、 模型的优缺点及其推广
7.1 问题1:信号灯周期估计模型
优点:
利用车辆行为与信号灯状态的关联性,无需直接观测信号灯即可估计周期,具有非侵入性和低成本的优势。
通过车辆速度变化特征提取红绿灯持续时间,避免了直接判断红绿灯状态的不确定性。
综合多辆车的数据进行估计,提高了估计的稳健性和抗噪声能力。
缺点:
假设车辆行为完全依赖信号灯状态,而忽略了其他因素(如道路拥堵、天气条件等)的影响。
未考虑车辆的个体差异性,如不同车型、驾驶习惯等,可能影响速度变化模式。
对数据质量和采样频率要求较高,数据缺失或稀疏时估计精度可能下降。
推广:
引入更多影响车辆行为的因素,如道路占有率、天气条件等,建立更全面的车辆行为模型。
考虑车辆的异质性,对不同类型的车辆进行分类建模,提高估计的精细度。
利用数据插值、平滑等技术处理数据缺失和噪声,提高模型的适应性。(后略)
2024华中杯B题思路论文汇总
https://www.yuque.com/u42168770/qv6z0d/xpkf6ax8udqq9lt2?singleDoc#